

1.1 并发编程的三大特性
可见性
有序性
原子性
1.1.1.1 可见性
话不多说,先看下面的代码
public class test01 {
public static long COUNT = 10_0000_0000L;
private static class T {
// private long p1,p2,p3,p4,p5,p6,p7;
public long x = 0L;
// private long p9,p10,p11,p12,p13,p14,p15;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
Thread t1 = new Thread(()->{
for(long i = 0 ; i < COUNT ; i++){
arr[0].x = i;
}
countDownLatch.countDown();
});
Thread t2 = new Thread(()->{
for(long i = 0 ; i < COUNT ; i++){
arr[1].x = i;
}
countDownLatch.countDown();
});
final long start = System.nanoTime();
t1.start();
t2.start();
countDownLatch.await();
System.out.println((System.nanoTime() - start) / 1000 );
}
}
该代码执行完所花费的时间为:

然而把该代码中的注释放开后,所花费的时间为:
 可以看到,我们多声明了几个变量,反而执行时间却变快了。 这是为什么呢?
可以看到,我们多声明了几个变量,反而执行时间却变快了。 这是为什么呢?
其原因是计算机底层在运行程序时,每一条指令都会在CPU中去执行。如果cpu每次都要从内存中去取数据,那么等待的时间肯定是很长的。所以就有了CPU高速缓存(Cache Memory)。
有了CPU高速缓存虽然解决了效率问题,但是它会带来一个新的问题:数据一致性。在程序运行中,会将运行所需要的数据复制一份到CPU高速缓存中,在进行运算时CPU不再与主存打交道,而是直接从高速缓存中读写数据,只有当运行结束后才会将数据刷新到主存中。
解决缓存一致性方案有两种:
通过在总线加LOCK锁的方式
通过缓存一致性协议
缓存一致性协议(不同的cpu厂商有着不同的缓存一致性协议)
存在的意义:CPU高速缓存是为了解决CPU速率和主存访问速率差距过大问题。
.png) 一般我们使用的是L1、L2、L3 三级缓存
一般我们使用的是L1、L2、L3 三级缓存

但要是我使用一个数据,就去内存取一个写入缓存里,还不如不使用缓存呢,这样反而更麻烦了。所以它在取数据的时候,会把该条数据周边的数据也一并取出来。那么一次取多少数据比较合适呢?
答案是 取64个字节
每一次存到缓存中的64个字节称为缓存行
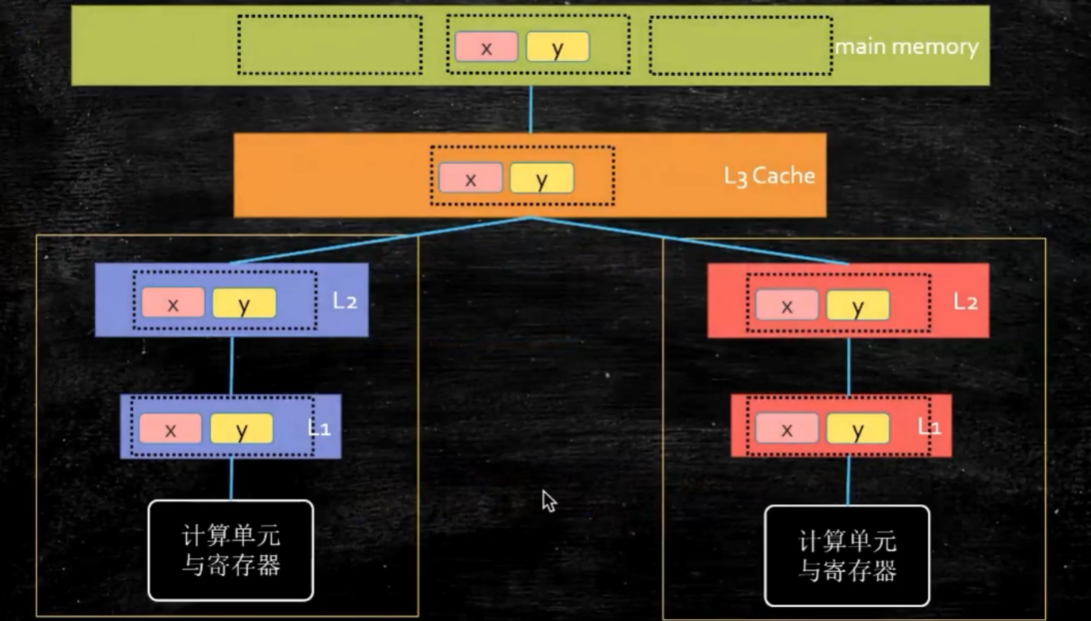
那么L1缓存中将数据改变了,我们该如何通知其他的缓存在更新数据呢? 这个问题也就是并发编程的可见性特征。
介绍这么多了,下面来看我们开头执行的这个代码。
如果我们只声明了一个X变量,那么t1、t2线程在执行时cpu存储的缓存行中,大概率X是在一起的,那么cpu1改了数据,还要去通知更新cpu2的缓存数据。
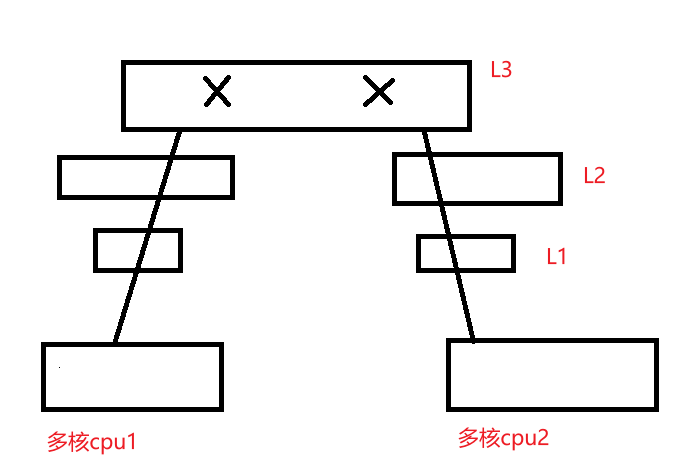
如果我们在X变量前后声明了几个变量,因为Long类型占8个字节,使得两个X不在同一个缓存行中,那么cpu1修改了数据则不需要去通知更新cpu2的缓存行数据。大大提升了效率。

并发框架Disruptor
Disruptor底层代码中使用的就是缓存一致性协议。
1.1.1.2 有序性
1.1.1.3 原子性
未完待续……
评论区